OCR in .NET using Tesseract
Tesseract has been around the block a few times. It was originally developed in the 80s by HP and released as open source software by Google in 2005. The most current version is Tesseract 5️⃣ which we can install via nuget package. Are there better options out there? For sure, but in terms of compatability not really. The more powerful OCR engines that can detect handwriting usually require a GPU. That is a big ask if you are trying to host the application yourself.
Setup
Getting started is easy on .NET
It is the first thing to pop up when searching for it on Nuget
Note: After installation, you'll notice a x64 and x86 folder in your project, this is part of the nuget package and is required for operation. That means you'll need to deploy the folders along with your application
We now need a language file, you can download those from here or you can grab the english one directly from here
You need to place these language files within a /tessdata folder (it is a hard coded requirement that the language files reside within this folder name)
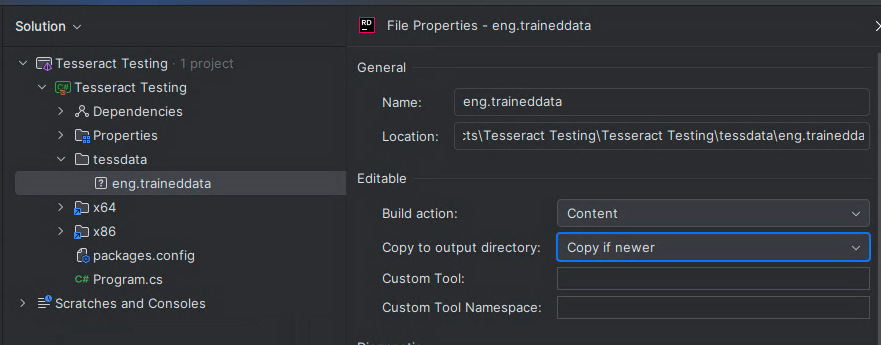
Make sure to set the build output to copy if newer
The build folder should look like this:
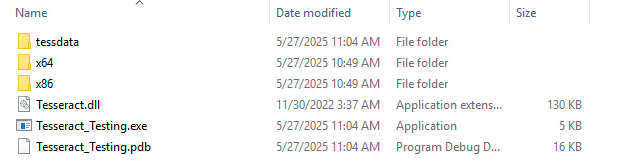
That's it! We should be ready to use the engine now
Basic Usage
Here is a basic usage example
using System;
using Tesseract;
namespace Tesseract_Testing
{
internal class Program
{
public static void Main(string[] args)
{
string imagePath = @".\testfiles\Random Text.tiff";
using (var engine = new TesseractEngine(@".\tessdata", "eng", EngineMode.Default))
{
using (var img = Pix.LoadFromFile(imagePath))
{
using (var page = engine.Process(img))
{
Console.WriteLine(page.GetText());
}
}
}
}
}
}
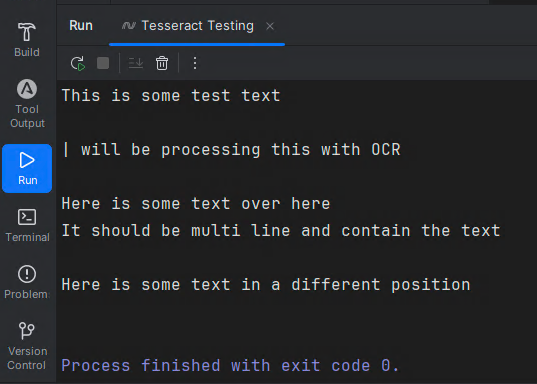
All we are doing here is loading our test file and printing the OCR results to the console
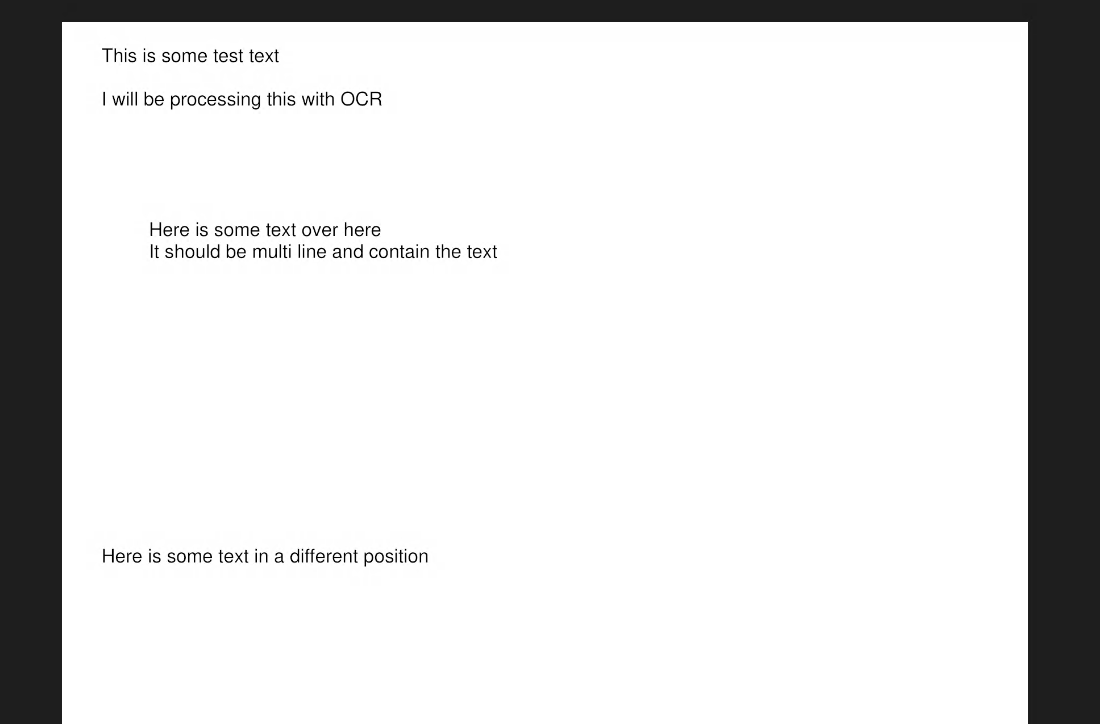
Trained Data Files
There are 100 languages that can be OCR'd with Tesseract
Each language is trained into a traineddata file and there are 3 levels of trained data available
- Normal: tessdata
- Fast: tessdata_fast
- Best: tessdata_best
The same languages and scripts are available from https://github.com/tesseract-ocr/tessdata_best. tessdata_best provides slow language and script models. These models are needed for training. They also can give better OCR results, but the recognition takes much more time.
Both tessdata_fast and tessdata_best only support the LSTM OCR engine.